

И снова привет, сейчас покажем как мы ведём у себя хранение данных в Dremio и как мы у себя условились называть датасеты и поля в них, приятного чтения! ![]()
- Структуризация хранения
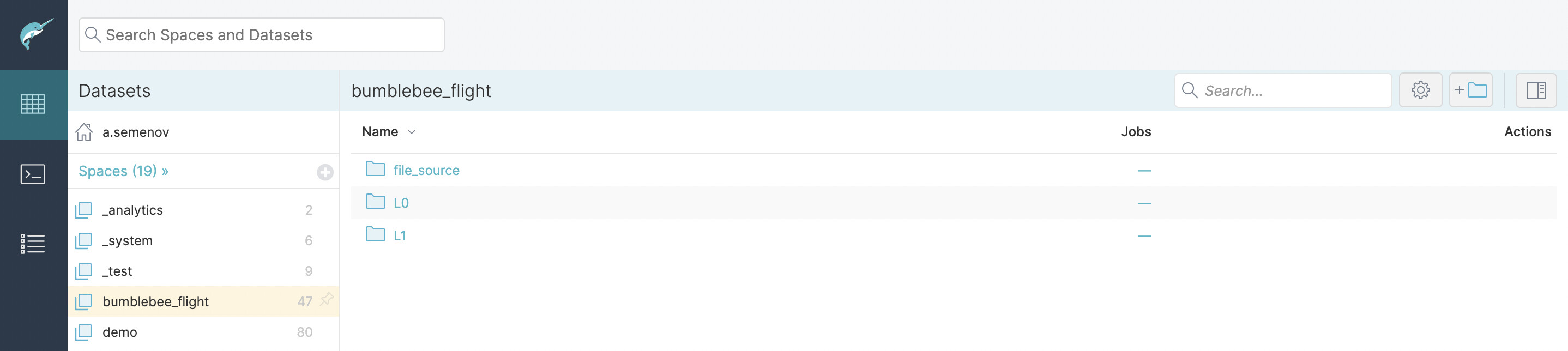
Для структурированного хранения данных существует система пространств (spaces) и папок (folders). Конкретно в этом разделе будет уделено внимание системе папок.
Перед созданием папочной структуры на проекте следует примерно представить какие типы источников будут использоваться, и будет ли часть конечных датасетов служить промежуточными для другой части. Рекомендуется начинать с базового уровневого подхода, при необходимости видоизменяя его под свои нужды с сохранением общей читаемости структуры.
При уровневом подходе датасеты хранятся по своеобразным уровням (источники – в “подвале”, промежуточные переиспользуемые датасеты – на первом этаже, конечные – на втором).
Пример следующей уровневой структуры приведен ниже:
- db_source – дубли таблиц из баз источников с необходимым набором полей;
- L0 – первичная подготовка переиспользуемых данных (т.е. объемные датасеты, служащие источником для последующих трансформаций);
- L1 – промежуточные датасеты;
- L2 – конечные датасеты.
Не исключена ситуация с большИм количеством уровней, как и ситуация, когда такого строгого разделения придерживаться не получится, и конечные датасеты будут находиться на различных уровнях. Это нормальная ситуация, так как основная идея подобной структуры – иметь представление о преемственности датасетов (т.е. для датасетов на L0 источником могут служить только датасеты с уровня db_source/папки с загруженными файлами, для L1 – L0, для L2 – L0 и L1, и т.д.), то есть не должно быть ситуации, когда датасет ссылается на датасет, находящийся на том же уровне.
- Правила именования пространств
Для именования пространств с проектами используется имя проекта и имя решения на латинице. Не стоит писать англоязычных аналогов (только если у самого проекта нет англоязычного названия), лучше использовать транслит.
Чеклист для именования пространства с проектом:
- транслит/прямое англоязычное название проекта+решения;
- для разделения слов используется “_”;
- только нижний кейс.
Т.е. если заказчик условный TTT, а решение называется Insight, то папка с проектом может называться ttt_insight.

Для именования папок с подпроектами применяются рекомендации по наименованию пространств.
Для именования папок по уровневной структуре:
- db_source – папка с дублями таблиц из бд-источников;
- file_source – папка с дублями загруженных файлов (если проект на отдельном инстансе возможно использовать папку в домашнем пространстве);
- L[0-n] – наименования папок с уровнями.
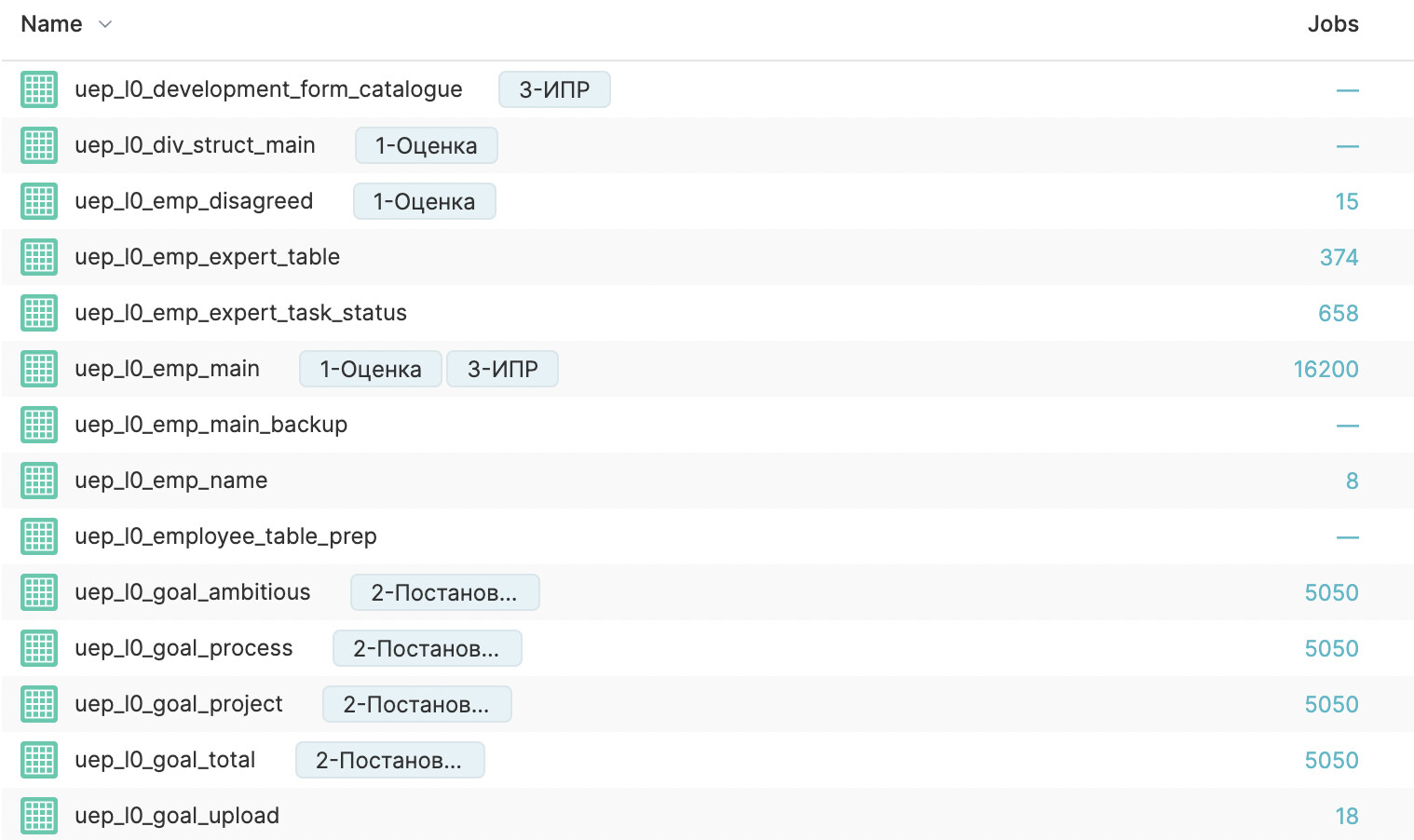
- Правила именования датасетов
Общая схема:
(путь)(основная сущность)[(пояснение1)(пояснениеN)][(особенность1)(особенностьN)](виджет)
Именование датасетов несколько отличается от именования папок, так как в названии датасета для удобства необходимо иметь не только описание сущности хранимых данных, но и его местоположение в существующей структуре для упрощения навигации.
В именовании используются английские слова, без транслита. Если транслит неизбежен из-за аббревиатур, то это допустимый сценарий. В то же время необходимо понимать, что работать с датасетами будет большое количество людей, и именования должно быть доступно и понятно всем.
Пример: есть датасет с данными по постановке целей (оно же целеполагание). Отразить содержимое этого датасета с помощью английского достаточно сложно, т.к. не все видят разницу между английским словами goal (правильно) и target (неправильно), что затем может вылиться в недопонимания, особенно если использовать онлайн-переводчики.
Названия можно и нужно сокращать, если это возможно без потери смысла.
Писать названия сущностей рекомендуется в единственном числе в целях поддержания единообразия.
После выбора основного названия датасета к нему добавляются префиксы и постфиксы.
К префиксам относится место этого датасета в структуре проекта и название проекта. Т.е. если датасет находится по пути l1, префиксом будет l1_, а название проекта ttt, то ttt_ – первый префикс (на базе предыдущего примера: название примет вид ttt_l1_goal_setting).
К постфиксам относятся:
- Дополнительные пояснения к сущности датасета (есть несколько датасетов с одной главной сущностью, но с некоторыми отличиями);
- важные особенности датасета (наличие накопительного итога, форматированных полей, данные только в определенном временном/оргструктурном/ином разрезах);
- Под какой инструмент визуализации (далее – виджет) подготовлен датасет, если он подготовлен под конкретный виджет.
Порядок в списке дан в порядке приписывания постфиксов к названию датасета.
На базе предыдущего примера:
- На уровне L1 мы имеем подготовительный датасет по целеполаганию, значит следует добавить первый дополнительный постфикс, который будет говорить о том, что он подготовительный. Название примет вид ttt_l1_goal_setting_prep;
- в этом датасете находятся данные агрегированные в разреза до подразделения и до месяца, значит добавляются следующие два постфикса: ttt_l1_goal_setting_div_month;
- датасет подготовлен специально под виджет пайчарт (диаграмма-пирог), добавляется последний постфикс: ttt_l1_goal_setting_div_month_pie.
Ниже приведен список постфиксов для примера:
- Подготовительный: prep(arational);
- Агрегированный: aggr(egated);
- Со всеми основными данными по сущности: main;
- Во временных разрезах час/день/неделя/месяц/квартал/год: hour/day/week/month/quarter/year;
- В оргструктурных разрезах: div(ision), store, manager;
- Имеет накопительный итог: rolling;
- Дубль с дополнительным форматированием: format(ted);
- Для виджетов: pie(chart), bar(chart), spline, table.
Если для существующего датасета поменялась логика формирования, но выходной формат остался неизменным, - изменения вносятся в существующий датасет и именование полей менять нельзя.
Если для существующего датасета поменялась логика формирования, то старый необходимо переименовать в название_backup, чтобы сохранить предыдущую версию, и создать новый датасет с тем же названием.
- Правила именования полей
Общая схема:
(основная сущность)[(пояснение1)(пояснениеN)](тип данных)[(особенность1)_(особенностьN)]
Именование полей схоже в своих принципах с именованием датасетов, но префиксов у них нет. У наименования поля так же выделяется сущность и так же добавляются постфиксы.
Используется только латиница, только английские аналоги, только нижний кейс, слова разделяются “_”.
К постфиксам полей относятся:
- Дополнительные пояснения к сущности поля (есть несколько полей с одной главной сущностью, но с некоторыми отличиями);
- тип данных, хранящихся в поле;
- важные особенности поля (наличие накопительного итога, форматирование, данные только в определенном временном/оргструктурном/ином разрезах).
Предположим, что в датасете есть поле с оргструктурным разрезом, поле с временным разрезом, поле со значением и поле с форматированным временным разрезом:
- Выделяется главная сущность у каждого поля: division, date, revenue, date;
- добавляются дополнительные пояснения к сущностям, где это необходимо: date_from, revenue_plan (в поле revenue хранятся плановые значения, date – зарезервированное слово в большинстве субд);
- добавляются пояснения к типу данных в полях, где это необходимо: division_id, revenue_plan_value (в поле division находятся идентификаторы подразделений, в поле revenue_plan - числовые значения);
- добавляются пояснения к важным особенностям поля, где это необходимо: revenue_plan_value_rolling, date_from_format (в поле revenue_plan_value находится накопительный итог, в форматированном поле date_from находится дата в другом формате для отображения на виджете).
Ниже приведен список постфиксов для примера, которые можно использовать:
- Идентификатор: id;
- Код (к примеру код подразделения по документам, но который не является идентификатором в данных): code;
- Дата: from (с даты), to (по дату), week, month, quarter, year, prev (предыдущий период);
- Время: from (с времени), to (по время);
- Форматированные значения: format;
- Наименования: name, short (сокращенное), full (полное), abbr (аббревиатура);
- Текстовые значения: text, desc (описание);
- Числовые значения: value, avg, count, quantity, diff (отклонение), percent (доля), max, min, total (если поле агрегировано до уровня выше минимального орг. разреза), hour, day, week, month, quarter, year, prev, rolling (накопительный итог);
- Вспомогательные: key (ключ строки), weight (удельный вес), icon (иконка для виджета), photo (ссылка на фото), order (порядок сортировки).